DeepSeek首次晒出账单!日赚346万元,理论利润率达545%



周末,DeepSeek又放大招,首次披露大模型的盈利情况,引爆投资圈。
理论利润率达545%
3月1日,DeepSeek发文披露了大规模V3、R1部署的成本和收益,成为了第一个详细披露了自己成本结构的大模型公司。
据DeepSeek计算,运营一天V3和R1的算力成本为87072美元,而以R1定价来看,收入理论上为562027美元,利润率为545%。
据介绍,DeepSeek V3和R1的所有服务均使用H800 GPU,使用和训练一致的精度。
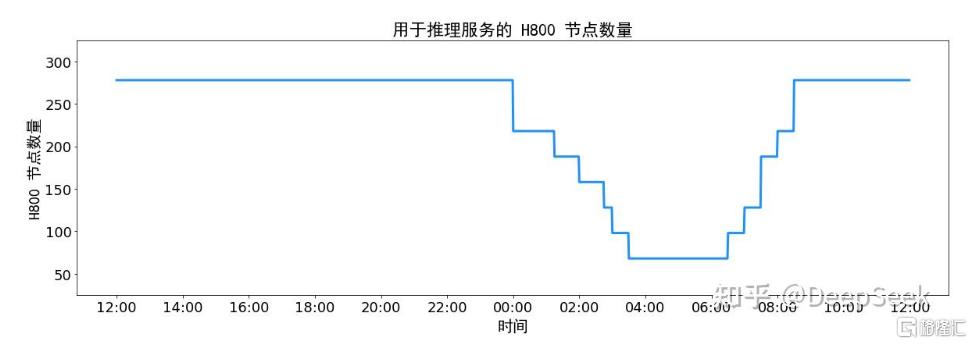
由于白天的服务负荷高,晚上的服务负荷低,因此DeepSeek实现了一套机制。在白天负荷高的时候,用所有节点部署推理服务。晚上负荷低的时候,减少推理节点,以用来做研究和训练。
在2025年02月27日12:00至2025年02月28日12:00,DeepSeek V3和R1推理服务占用节点总和,峰值占用为278个节点,平均占用226.75个节点(每个节点为8个H800 GPU)。假定 GPU 租赁成本为2美金/小时,总成本为87,072美元/天。
在24小时统计时段内,DeepSeek V3和 R1的网页、APP和API的所有负载如下:
输入token总数为608B,其中 342B tokens(56.3%)命中KVCache硬盘缓存。
输出 token总数为168B。平均输出速率为20~22tps,平均每输出一个token的KVCache长度是4989。
平均每台H800的吞吐量为:对于prefill任务,输入吞吐约73.7k tokens/s(含缓存命中);对于decode任务,输出吞吐约14.8k tokens/s。
如果所有tokens全部按照DeepSeek R1的定价计算,理论上一天的总收入为562,027美元(折合人民币409.36万元),成本利润率545%。
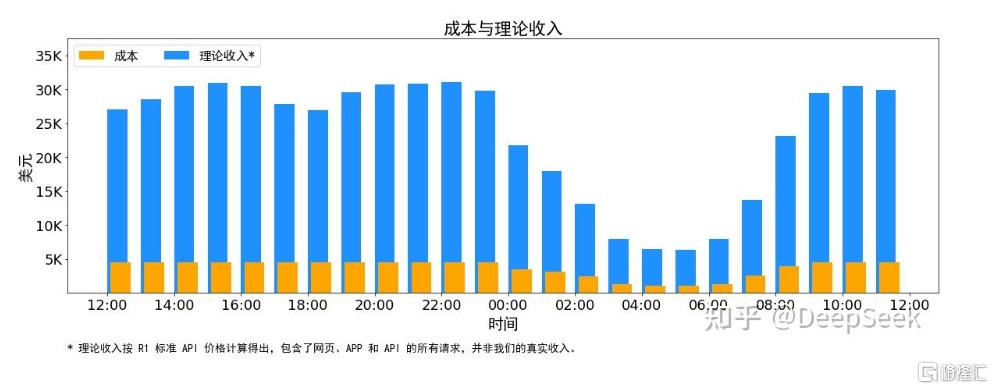
以此计算,DeepSeek理论上最高每天可盈利47. 5万美元(折合人民币约346万元)。
不过,DeepSeek也表示,实际上没有这么多收入,因为V3的定价更低,同时收费服务只占了一部分,另外夜间还会有折扣。
巨大的盈利下,有投资人开始按计算器,称其在美国应该是一家估值超百亿美元的公司。
MenloVentures投资人Deedy表示:“理论ARR(年收入)2亿美元、利润率超过500%,这样的商业效率理应是一家值100亿美元的公司。”

还有网友评论,DeepSeek掀起了行业新一轮卷Infra热潮。
DeepSeek官方直接披露内部的成本利润细节,这下所有做Infra的兄弟都要被老板上压力了——如果利润率达不到DeepSeek的水平,就说明自家的Infra团队菜。
开源周收官
上周,DeepSeek进行了开源周,连续放了5天Infra相关的库。
第一天,开源项目 FlashMLA 正式发布,专为Hopper GPU优化的高效MLA解码内核,支持变长序列处理。

第二天,DeepEP发布,DeepEP是一个专为混合专家系统(MoE)和专家并行(EP)设计的通信库。

第三天,DeepGEMM发布,DeepGEMM 是一个专为简洁高效的FP8通用矩阵乘法(GEMM)设计的库,具有细粒度缩放功能。

第四天,DualPipe与EPLB发布,DualPipe是一种创新的双向管道并行算法。EPLB即专家并行负载均衡器,自动平衡GPU负载,避免部分显卡过载或闲置。
最后一天,3FS文件系统发布,并行文件系统Fire-Flyer File System,利用SSD和RDMA网络技术,显著加速数据处理。

周六,DeepSeek又披露了盈利情况,算是为开源周做了一个很好的收尾。
交易商排行
更多- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管88.77
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管85.36
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中金点国际集团 GD International Group澳大利亚| 1-2年86.64
- 监管中Moneta Markets亿汇澳大利亚| 2-5年| 零售外汇牌照80.52
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.81
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.56
- 监管中GO Markets高汇15-20年 | 澳大利亚监管 | 塞浦路斯监管 | 塞舌尔监管87.90
- 监管中alpari艾福瑞5-10年 | 白俄罗斯监管 | 零售外汇牌照87.05
- 监管中AUS Global5-10年 | 塞浦路斯监管 | 澳大利亚监管86.47