英伟达官宣下一代最强AI芯片 GPU性能8年提高1053倍



在当今计算、网络和图形技术的发展历史上,英伟达有许多独特之处。其中之一就是,它现在手头资金雄厚,而且凭借其架构、工程设计和供应链,在人工智能生成市场上占据了领先地位。因此,英伟达可以随心所欲地规划未来的发展路线图,只要有助于推动技术进步。
早在2000年代,英伟达就已经是一家非常成功的创新企业,实际上并不需要涉足数据中心计算领域。但是,高性能计算(HPC)研究人员将英伟达拉入了加速计算领域,然后人工智能研究人员利用GPU计算优势,创造了一个全新的市场,这个市场已经等待了四十年,等待着以合理的价格将大量计算与海量数据相碰撞,真正实现把类似“思维机器”的东西带进到日常生活中。
致敬Danny Hillis、Marvin Minsky和Sheryl Handler,他们在1980年代创立了Thinking Machines,试图为AI处理提供支持,而不是传统的HPC模拟和建模应用。
同样,Yann LeCun在AT&T贝尔实验室创造卷积神经网络时,既没有数据也没有计算能力来制造我们现在所知的人工智能。
当时,黄仁勋是LSI Logic公司的主管,该公司生产存储芯片,黄仁勋最终成为AMD公司的CPU设计师。20世纪90年代初,就在Thinking Machines正处于艰难时期(最终破产),黄仁勋与Chris Malachowsky和Curtis Priem在圣何塞东边的Denny's餐厅会面,并创立了Nvidia。
Nvidia从超级分频器领域看到了新兴的人工智能机遇,并开始构建系统软件和底层大规模并行硬件,以实现人工智能革命的梦想。
这一直是计算的终极状态,也一直是我们所迈向的奇点。
如果其他星球上存在生命,那么生命总会进化到拥有大规模杀伤性武器的地步,总会创造出人工智能。可能也是在同一时间。在那一刻之后,这个世界会如何处理这两种技术,才是决定其能否在大灭绝事件中幸存下来的关键。
这听起来不像是讨论芯片制造商路线图的正常开场白。但事实并非如此,这是因为我们生活在一个充满变革的时代。
在台湾台北举行的年度电脑展(Computex)上,Nvidia的联合创始人兼首席执行官黄仁勋在其主题演讲中,再次试图将生成式人工智能革命(他称之为“第二次工业革命”)置于其背景之下,并展示了AI的未来,尤其是英伟达硬件的未来。
由此,我们窥见了GPU和互联技术路线图。但是据我们所知,这并不是计划的一部分,黄仁勋和他的主题演讲通常都是最后一刻才真正开始。
01.革命不可避免
黄博士提醒我们注意:生成式人工智能的核心在于规模。同时也指出2022年底ChatGPT时刻的到来既有技术方面的原因,也有经济方面的原因。
要达到ChatGPT的突破性时刻,需要GPU性能的大幅增长,然后再加上大量的GPU。
Nvidia确实实现了性能,这对人工智能的训练和推理都很重要,而且重要的是,它还从根本上减少了生成作为大型语言模型响应一部分的标记所需的能量。我们来看一下:
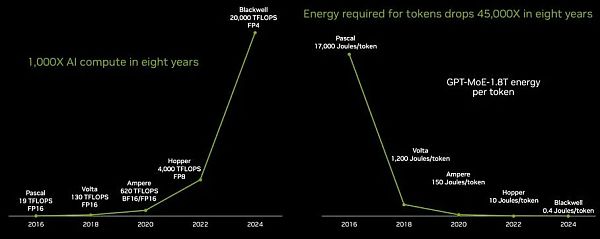
在八年间,从“Pascal P100 GPU”到“Blackwell B100 GPU”,GPU的性能提高了1053倍。其中部分性能是通过降低浮点精度实现的,例如从Pascal P100、Volta V100和Ampere A100 GPU的FP16格式到Blackwell B100使用的FP4格式,降低了4倍。
由于在数据格式、软件处理和硬件方面运用了大量的数学魔法,如果不降低精度,性能提升将只有263倍,而降低精度不会对LLM性能造成实质性损害。要知道,在CPU市场上,每时钟核心性能提高10%至15%,核心数量增加25%至30%已属正常。如果升级周期为两年,那么在同样的八年时间里,CPU吞吐量将提高4至5倍。
如上图所示,单位功耗的降低是一个关键指标,因为如果无法为系统供电,就无法使用系统。而token的能耗成本必须降低,这意味着为LLM生成的每个token的能耗必须比性能提升的速度更快。
在黄仁勋的主题演讲中,为了给大家提供一些更深层次的背景信息,在Pascal P100 GPU上生成一个token所需的17000焦耳热量大约相当于两个灯泡运行两天,而平均每个字需要三个token。
因此,现在我们开始明白为什么八年前的LLM甚至不可能在一定规模上运行,使其在执行任务时表现出色了。下图是在1.8万亿个参数、8万亿个通证数据驱动模型的情况下,训练GPT-4 Mixture of Experts LLM所需的功率:

对于一个P100集群来说,超过1000千兆瓦时的电量实在是太大了。
黄仁勋解释道:有了Blackwell GPU,公司将能够在大约10天内通过大约1万个GPU来训练GPT-4 1.8T MoE模型。
如果人工智能研究人员和Nvidia没有转向更低精度,那么在这八年时间里,性能提升也不过是250倍。
降低能源成本是一回事,降低系统成本又是另一回事。在传统的摩尔定律末期,晶体管每隔18到24个月就会缩小一次,芯片变得越来越便宜、越来越小,这两种技巧都非常困难。
现在,计算复合体已经达到了微粒极限,每个晶体管都越来越昂贵,因此,由晶体管制成的设备本身也越来越昂贵。HBM内存是成本的重要组成部分,先进的封装也是如此。
黄仁勋本人今年早些时候在接受CNBC采访时就曾说过Blackwell的价格。在SXM系列GPU插座中(不包括PCI-Express版本的GPU),P100推出时的成本约为5000美元;V100约为1万美元;A100约为1.5万美元;H100约为2.5万至3万美元。B100的成本预计在3.5万美元到4万美元之间。
黄仁勋没有说明的是,运行GPT-4 1.8T MoE基准每一代需要多少GPU,以及这些GPU或运行所需的电费是多少。
下图这个电子表格显示,根据黄仁勋所说,大约需要1万个B100,才能在十天左右的时间内训练出GPT-4 1.8T MoE:
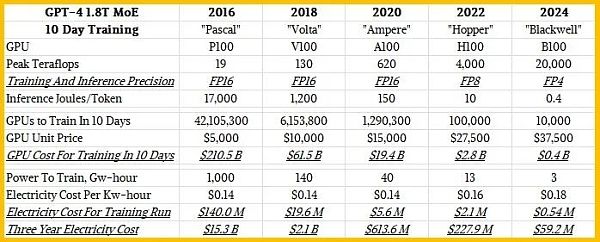
在这八年里,GPU的价格上涨了7.5倍,但性能却提高了1000多倍。因此,现在使用Blackwell系统,可以在十天左右的时间内实际训练出像GPT-4这样拥有1.8万亿个参数的大型模型,而在两年前,即使是在Hopper一代刚刚起步的时候,也很难在数月内训练出拥有数千亿个参数的模型。
现在,系统成本将与该系统两年的电费相当。GPU大约占人工智能训练系统成本的一半,因此购买一个1万个GPU的Blackwell系统大约需要8亿美元,而运行十天的电费大约需要54万美元。
如果购买更少的GPU,就可以减少每天、每周或每月的电费支出,但同时也会相应增加训练时间,使电费支出再次上升。
就是这样,即使Hopper H100 GPU平台是“史上最成功的数据中心处理器”,正如黄仁勋在Computex主题演讲中所说的那样,Nvidia仍需继续努力。
如果将Hopper/Blackwell的投资周期与六十年前IBM System/360的发布相比较,IBM在那次发布中下了至今仍是公司历史上最大的赌注。
1961年,当IBM开始其“下一代产品线”研发项目时,它是一家年收入22亿美元的公司,在整个20世纪60年代,它花费了50多亿美元。
Big Blue是华尔街第一家蓝筹股公司,正是因为它花费了两年的收入和二十年的利润来创造System/360。它的某些部分推出较晚,表现不佳,但它彻底改变了企业数据处理的本质。
20世纪60年代末,IBM认为自己可能会创造600亿美元的销售额,但他们创造了1390亿美元的销售额,利润约为520亿美元。
可以说,Nvidia为数据中心计算的第二阶段掀起了更大的浪潮。
02.抵制是徒劳的
无论是Nvidia还是其竞争对手或客户,都无法抵挡未来的引力,也无法抵挡生成式人工智能对利润和生产力的承诺。
因此,Nvidia必将加快步伐,推陈出新。凭借250亿美元的银行存款和今年预计超过1000亿美元的收入,或许还有500亿美元将进入银行,它有能力推陈出新,把我们所有人都拉进未来。
黄仁勋表示:“在这个令人难以置信的增长时期,我们要确保继续提高性能,继续降低成本,如训练成本、推理成本等,并继续扩展人工智能能力,让每家公司都能拥抱人工智能。我们把性能推得越高,成本下降得就越厉害。”
正如我们上面的表格所清楚显示的那样,事实的确如此。这就引出了最新的Nvidia平台路线图:
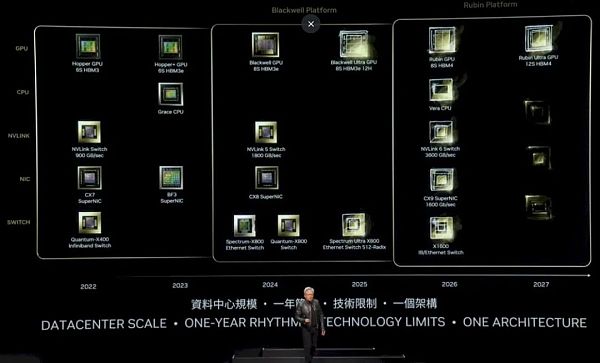
在Hopper这一代中,最初的H100于2022年推出,配备了六层HBM3内存堆栈,通过带有900 GB/s端口的NVSwitch连接,并配有400 Gb/s端口的Quantum X400(以前称为Quantum-2)InfiniBand交换机以及ConnectX-7网络接口卡。
2023年,H200升级到六层更高容量和带宽更高的HBM3E内存,从而提升了H200封装中底层H100 GPU的有效性能。BlueField 3网卡也问世了,它为网卡增加了Arm内核,使其可以进行辅助工作。
在2024年,Blackwell GPU当然已经推出了8堆HBM3e内存,并与配备1.8TB/sec端口的NVSwitch 5和800Gb/sec的ConnectX-8网卡,以及配备800GB/sec端口的Spectrum-X800和Quantum-X800交换机搭配使用。
现在我们可以看到,在2025年,B200(上图中称为Blackwell Ultra)将拥有8个堆栈的HBM3e内存,这些堆栈有12个芯片高。
据推测,B100中的堆栈有8层高,因此Blackwell Ultra的HBM内存容量至少增加了50%,根据所使用的DRAM容量,增幅可能更大,HBM3E显存的时钟速度也可能更高。
Nvidia对Blackwell系列的内存容量含糊其辞,但我们在3月份的Blackwell发布会上估计,B100将拥有192GB内存和8TB/秒的带宽。
对于未来的Blackwell Ultra,我们预计会有更快的内存出现,如果出现带宽为9.6TB/秒的288GB内存,我们也不会感到惊讶。
我们认为,Ultra变体在SM上的良品率有可能会有所提高,从而使其性能略高于非Ultra前代产品。这将取决于产量。
Nvidia还将在2025年推出弧度更高的Spectrum-X800以太网交换机,可能会在盒子里装上六个ASIC,以创建一个非阻塞架构,就像其他交换机常用的那样,将总带宽翻倍,从而将每个端口的带宽或交换机中端口的数量翻倍。

在2026年,我们看到了“Rubin R100 GPU”,在去年发布的Nvidia路线图中,它的前身是X100,正如我们当时所说,我们认为X是一个变量,而不是任何东西的简称。
事实证明确实如此,Rubin GPU将使用HBM4内存,并将有8个堆栈,每个堆栈可能有十几个DRAM高,而2027年的Rubin Ultra GPU将有十几个HBM4内存堆栈,也可能有更高的堆栈(虽然路线图没有这么说)。
我们直到2026年才会看到Nvidia推出新的Arm服务器CPU“Vera”,它是当前“Grace”CPU的继任者。与之配套的是NVSwitch 6芯片,具有3.6 TB/s的端口,以及带有1.6 Tb/s端口的ConnectX-9网络接口卡。
有趣的是,还有一款名为X1600 IB/Ethernet Switch的产品,这可能意味着Nvidia正在融合其InfiniBand和以太网ASIC,就像十年前Mellanox所做的那样。或者,这可能意味着Nvidia只是为了好玩而试图让我们产生怀疑。
2027年的路线图中还透露了一些其他信息,这可能意味着对网卡和交换机的全面超以太网联盟支持,甚至可能是用于将节点内和跨机架的GPU连接在一起的UALink交换机。
原文来源于:
https://www.nextplatform.com/2024/06/02/nvidia-unfolds-gpu-interconnect-roadmaps-out-to-2027/
中文内容由元宇宙之心(MetaverseHub)团队编译,如需转载请联系我们。
来源:金色财经
交易商排行
更多- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管88.77
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管85.36
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中金点国际集团 GD International Group澳大利亚| 1-2年86.64
- 监管中Moneta Markets亿汇澳大利亚| 2-5年| 零售外汇牌照80.52
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.71
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.56
- 监管中GO Markets高汇15-20年 | 澳大利亚监管 | 塞浦路斯监管 | 塞舌尔监管87.90
- 监管中alpari艾福瑞5-10年 | 白俄罗斯监管 | 零售外汇牌照87.05
- 监管中AUS Global5-10年 | 塞浦路斯监管 | 澳大利亚监管86.47