联想车计算发布智驾平台大模型中间件 Ultra Boost



日前,在NVIDIA GTC 2024上,联想车计算发布了全新的支持包括NVIDIA DRIVE等平台的大模型中间件Ultra Boost,包括AI模型引擎及AI编译器等工具链,旨在助力大模型在车端部署,结合多模态的人机交互技术,赋能车内智能拓展更多应用场景。在CES 2024上联想首次展示了基于汽车场景大模型的座舱智能助理,在此次GTC2024上,车计算团队利用大模型中间件 Ultra Boost快速地将该智能助理应用部署至NVIDIA DRIVE平台。
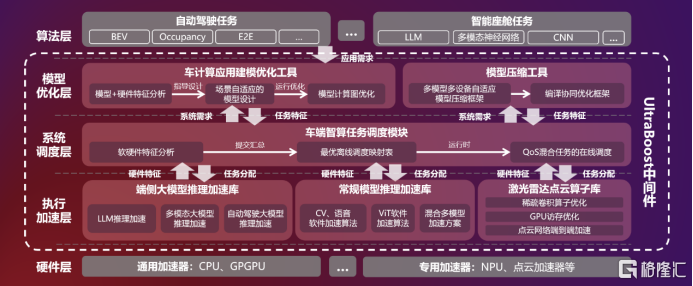
联想车计算智驾平台大模型中间件 Ultra Boost架构图
大模型生态快速崛起,AI应用需求日益复杂,模型部署面临巨大机遇与挑战。与此同时汽车AI芯片的迭代也需要兼顾不同应用需求。芯片架构需要适配AI算法模型以及增加算法模型引擎。为了提高 AI 计算效率,特别是针对基于 transformer 的算法,下一代 NVIDIA DRIVE Thor 平台采用 Blackwell 架构,可实现生成式 AI 功能,该系统在 NVIDIA 最先进的数据中心 AI 解决方案上进行了训练。
与此同时,为了进一步发挥AI芯片平台的性能,加速客户的AI开发和部署效率,联想推出了AI模型引擎Ultra Boost:针对NVIDIA DRIVE平台,该引擎将提供一套软硬一体的端到端AI性能优化方案。在应用层,提供场景自适应的建模优化工具、硬件感知的模型压缩工具,可在极低的精度损失范围内大幅降低模型计算量;在调度层,提供专用于自动驾驶的调度中间件,该中间件基于自研的静态+动态调度算法打造,在保证实时性的同时提升了系统的执行效率;在执行层,该引擎提供多种算法加速库,涵盖AI大模型加速、多媒体任务流加速、激光雷达点云加速,应用场景可覆盖智能座舱和自动驾驶;在编译层,联想车计算自研的AI编译器SpeedWise,可针对普通模型和大模型,以及不同目标硬件完成编译和优化。
在此基础上,联想车计算推出的AI模型引擎,基于英伟达AI芯片的多项技术,包括Continuous Batching来提升推理吞吐率,降低推理时延;面向硬件Graphic Rewriting技术来优化大模型网络结构的同时,还基于联想车计算自研的大模型低比特量化技术来加速大模型推理,并且建立了面向NVIDIA DRIVE平台的自动调优机制实现了全自动的模型优化,快速且成功的将联想自己的智能助手应用部署。
联想车计算此次发布的面向智能驾驶的AI中间件 Ultra Boost,支持业界多个主要大模型的自动化部署和加速,将助力客户缩短开发周期,打造性能卓越,成本更优的智能驾驶解决方案。

在NVIDIA GTC 2024上,联想车计算展示了多款自动驾驶域控平台。
交易商排行
更多- 监管中EXNESS10-15年 | 英国监管 | 塞浦路斯监管 | 南非监管92.42
- 监管中FXTM 富拓10-15年 |塞浦路斯监管 | 英国监管 | 毛里求斯监管88.26
- 监管中axi15-20年 | 澳大利亚监管 | 英国监管 | 新西兰监管82.80
- 监管中GoldenGroup高地集团澳大利亚| 5-10年85.87
- 监管中Moneta Markets亿汇澳大利亚| 2-5年| 零售外汇牌照80.52
- 监管中GTCFX10-15年 | 阿联酋监管 | 毛里求斯监管 | 瓦努阿图监管69.35
- 监管中IC Markets10-15年 | 澳大利亚监管 | 塞浦路斯监管91.81
- 监管中金点国际集团 GD International Group澳大利亚| 1-2年86.64
- 监管中VSTAR塞浦路斯监管| 直通牌照(STP)80.00
- 监管中CPT Markets Limited5-10年 | 英国监管 | 伯利兹监管91.56